[Java] 컬렉션 프레임워크 인터뷰 질문 40개
정리
- 자바 컬렉션 프레임워크는 무엇이고, 사용하므로서 얻는 이점은 무엇인가?
- 객체나 데이터들을 효율적으로 관리(추가, 삭제, 검색, 저장)하기 위해서 사용하는 라이브러리를 의미
- 이점
- 라이브러리 사용으로 인한 시간 감소
- 검증되어 있기 때문에 코드 품질 보장
- 재사용 가능
- 컬렉션 프레임워크에 제너릭스가 도입되면서 생긴 장점은 무엇인가?
- 잘못된 타입의 오브젝트를 세팅할 경우 컴파일 시점에서 파악 가능
- 클래스 캐스팅 및 instansof 를 사용하지 않아도 되므로써 코드를 간결하게 유지 가능
- 자바 컬렉션 프레임워크의 기본 인터페이스들은 무엇인가?
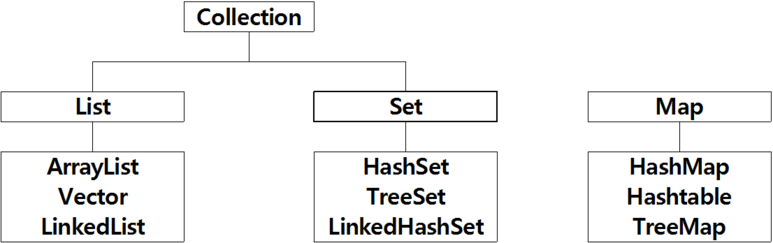
- Collection
- 가장 기본이 되는 인터페이스
- 자바는 이 인터페이스를 직접 구현한 클래스는 아무것도 제공하지 않음
- List
- 중복 허용
- 인덱스 순서로 저장
- Set
- 중복 불가
- 순서 없이 저장
- Map
- 키/값 동시 저장
- 키의 중복 불가
- 왜 컬렉션은 Cloneable 과 Serializable 인터페이스를 상속받지 않았는가?
- 컬렉션은 오브젝트들을 묶어서 관리하고 이를 어떻게 유지하는지는 관여하지 않는다.
- 컬렉션은 추상 인터페이스고 실제 구현체에서 어떻게 사용해야 될지를 결정해야 된다.
- 왜 Map 인터페이스는 컬렉션 인터페이스를 상속받지 않는가?
- Map은 컬렉션이 아니고 컬렉션 역시 Map이 아니다.
- 맵은 키-값 을 가지고 있고 컬렉션 처럼 키와 값들을 검색하는 메서드들을 하지만 이 것은 “엘리먼트들의 그룹”이라는 컬렉션 인터페이스의 기본 개념과 맞지 않는다.
- Iterator는 무엇인가?
- Iterator 인터페이스는 컬렉션이 반복적으로 수행하기 위한 메서드를 제공
- iterator 메서드를 통해 컬렉션으로 부터 iterator instance를 가져올 수 있다.
- 자바 컬렉션 프레임워크에서 Enumeration에 속한다.
- Enumeration 과 Iterator 인터페이스의 다른점은 무엇인가?
- Iterator
- 반복, 열거, 삭제 기능 제공
- 삭제 지원 - remove()
- 반복, 열거, 삭제 기능 제공
- Enumeration
- Iterator의 구버전
- 반복, 열거 기능 제공
- Iterator
- 왜 다른 컬렉션 처럼 Iterator.add() 메서드는 없는가?
- iterator에 add를 추가 한다면 이는 반복작업의 순서를 보장하지 않는다.
- ListIterator는 반복 작업을 할때 순서를 보장하기 때문에 add 기능을 제공한다.
- 왜 Iterator는 Cursor 없이 직접적으로 이동할 수 있는 next 메서드를 제공하지 않는가?
- iterator를 구현하는 클래스마다 이를 만들어 줘야 되기 때문에 제공되지 않는다. 그리고 Iterator(반복)이라는 의미와 맞지도 않는다.
- Iterator 와 ListIterator의 차이점은 무엇인가?
- Iterator 는 앞쪽으로 탐색을 하지만 ListITerator는 양방향 순회가 가능
- List를 반복할 수 있는 방법은 무엇인가?
- Iterator 사용
- Iterator는 thread-safe
- 반복 도중에 엘리먼트가 수정되려고 한다면 ConcurrentModificationException을 발생
- Iterator는 thread-safe
- for-each loop 사용
- Iterator 사용
- Iterator의 fail-fast에 대해 알고 있는것은 무엇인가?
- fail-fast
- 하부 콜렉션 객체에 변경이 일어나 순차적 접근에 실패하면ConcurrentModifincationException 예외 발생
- fail-fast
- fail-fast 와 fail-safe 의 다른 점은 무엇인가?
- fail-fast
- 사용하는 컬렉션들은 java.util 패키지에 들어가있다.
- ConcurrentModificationException 발생
- fail-safe
- 사용하는 컬렉션들은 java.util.concurrent 패키지에 들어가 있다.
- ConcurrentModificationException 발생 하지 않음
- fail-fast
- 컬렌션을 순회하는 도중에 ConcurrentModificationException이 발생하는것을 피할려면 어떻게 해야 되는가?
- concurrent 컬렉션을 사용하면 ConcurrentModificationException이 발생하는것 예방가능
- ex) ArrayList 대신 CopyOnWriteArrayList를 사용
- concurrent 컬렉션을 사용하면 ConcurrentModificationException이 발생하는것 예방가능
- Iterator 인터페이스의 구현체가 없는 이유는 무엇인가?
- 실제 구현은 컬렉션의 구현체가 가지고 있다.
- 모든 컬렉션 클래스들은 순회를 하기 위해 내부에 Iterator를 구현한 코드를 가지고 있다.
- 이를 통해 iterator가 fail-fast를 사용할지 fail-safe를 사용할지 결정할 수 있도록 한다.
- ArrayList의 Iterator는 fail-fast이고 CopyOnWriteArrayList의 Iterator는 fail-safe
- UnsupportedOperationException 은 무엇인가?
- 사용할려는 메서드가 제공되지 않을 때 발생하는 오류
- 자바에서 HashMap은 어떻게 동작하는가?
- HashMap 은 키-값 쌍으로 사용하도록 구현
- HashMap은 해싱 알고리즘을 사용하고 hashCode()와 equals()를 put() 과 get()을 쓸 때 사용
- put 메서드를 호출 시
- key의 hashCode()를 호출해서 맵에 저장되어 있는 값 중에 동일한 key가 있는지 찾는다.
- 이 Entry는 LinkedList에 저장되어 있고 만약 존재하는 entry면 equals()메서드를 사용해서 key가 이미 존재 하는지 확인
- 존재 한다면 value값을 덮어 씌워서 새로운 키-값 으로 저장
- get 메서드 호출 시
- key의 hashCode() 를 호출해서 array에서 값을 찾는다.
- equals()메서드를 가지고 찾고자 하는 key와 동일한지 확인한다.
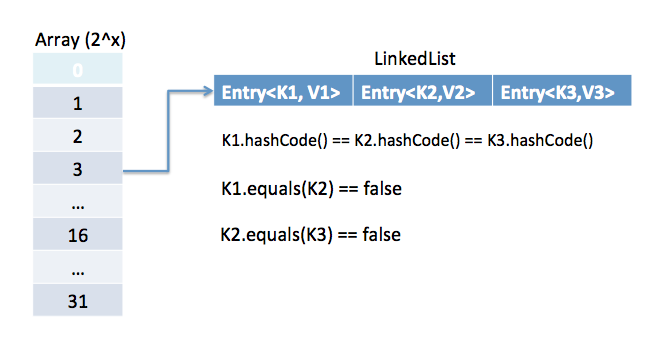
- hashCode()와 equals() 메서드의 중요점은 무엇인가?
- hashCode()와 eqauls()메서드를 사용해서 key-value 값을 저장할 위치를 결졍하고 HashMap에서 값을 꺼내올때도 사용
- 만약 이 메서드들이 올바르게 구현되지 않았다면 다른 두개의 Key가 같은 hashCode() 및 eqauls() 결과를 내놓을 수 있고 이는 value 값들을 잘못된 의도하지 않은 값으로 덮어 씌울 가능성이 있다.
- equals()와 hashCode()의 구현은 아래 기본룰을 따라야 된다.
If o1.equals(o2), then o1.hashCode() == o2.hashCode() should always be true. If o1.hashCode() == o2.hashCode is true, it doesn’t mean that o1.equals(o2) will be true. - 아무 클래스나 Map의 Key로 사용할 수 있는가?
- 아무 클래스나 사용 가능 하지만 아래 몇몇 주의사항을 따라야 된다.
- 클래스가 equals()를 overrides 했다면 hashCode() 역시 override 해야 한다.
- equals() 메서드가 사용되지 않으면 hashCode()도 사용하지 않아야 한다.
- 가장 좋은 방법은 key 클래스를 불변(immutable)으로 만드것이다
- hashCode() 값은 캐시되어 빠른 성능을 가진다.
- 불변 클래스는 hashCode() 및 equals()의 값이 변하지 않기 때문에 해당 값이 변해서 생기는 문제들을 해결할 수 있다.
- 아무 클래스나 사용 가능 하지만 아래 몇몇 주의사항을 따라야 된다.
- Map 인터페이스가 제공하는 다른 Collection 뷰는 무엇인가?
- Map 인터페이스는 아래 3가지 형태의 collection view 를 제공
- Set keySet()
- 맵에 존재하는 Key 값들을 Set으로 보여준다.
- 이 set들은 맵과 연결되어 있으며 맵을 바꾸거나 set을 바꾸면 값이 수정 된다.
- Set은 엘리먼트들을 지울 수 있고 이에 대응하는 값은 맵에서 삭제 된다.
- Collection values()
- 맵에 존재하는 Value 들을 컬렉션 형태로 보여준다.
- 맵과 연동되어 있으며 collection을 수정 하면 map의 값이 수정된다.
- Set<Map.Entry<K, V» entrySet()
- 맵의 entry 들을 Set 형태로 보여준다.
- Set keySet()
- Map 인터페이스는 아래 3가지 형태의 collection view 를 제공
- HashMap과 Hashtable의 차이점은 무엇인가?
- HashMap
- 키/값에 null을 허용
- 동기화 지원 하지 않음
- 단일 스레드 환경에서 더 좋은 퍼포먼스 보여줌.
- iterator 키 셋을 제공하므로 fail-fast 기능 사용
- Hashtable
- 키 / 값에 null 허용 하지 않음
- 동기화 지원 - synchronized
- 멀티 스레드 환경에 적합
- Enumeration 키를 사용하므로 fail-fast 기능 제공 못함
- HashMap
- HashMap과 TreeMap중 무엇을 사용할지 어떻게 판단하는가?
- HashMap : 엘리먼트들을 추가, 삭제, 위치 변경등의 작업 할 때
- TreeMap : 정렬되어 있는 key값에 따라 탐색 할 때
- ArrayList와 Vector간의 비슷한점과 차이점은 무엇인가?
- 비슷한 점
- 인덱스 기반, 내부적으로 배열로 백업 할 수 있다.
- 엘리먼트들을 추가한 순서를 가지고 있고 이 순서를 가져 올 수도 있다.
- iterator를 구현하였으므로 fail-fast 방식
- null 값을 가질 수 있고 인덱스 번호를 사용해 랜덤으로 접근 할 수 있다.
- 차이점
- Vector는 synchronized 되어 있지만 ArrayList는 그렇지 않다.
- iterating 중에 엘리먼트를 수정 하고 싶다면 CopyOnWriteArrayList를 사용하면 된다.
- ArrayList는 synchronized에 따른 간접비용이 아무것도 없기 때문에 Vector보다 빠르다.
- Vector는 synchronized 되어 있지만 ArrayList는 그렇지 않다.
- 비슷한 점
- Array와 ArrayList의 차이점은 무엇이고 언제 ArrayList를 사용해야 하는가?
- Array는 primivite 타입, Object 둘다 사용 가능, ArrayList는 Object만 사용 가능하다.
- ArrayList 사용할 때
- 리스트의 크기가 동적으로 변할 때
- 목록에 관련된 작업을 할 때
- 다양한 기능을 사용할 때(addAll, removeAll, iterator 등등)
- Array 사용할 때
- 리스트의 크기가 고정되어 있고 값을 저장하거나 탐색 용도로만 쓸 경우
- primitive 타입일 경우
- 다차원 배열을 사용할 경우 [][] 배열을 사용하는게 List<List<»를 쓰는것보다 쉽다.
- ArrayList와 LinkedList의 차이점은 무엇인가?
- ArrayList
- 인덱스 기반의 Array로 구성
- 랜덤 엑세스를 할 경우 속도는 O(1)
- LinkedList
- 데이터들이 이전, 다음 노드 처럼 서로 연결된 node로 구성
- LinkedList 의 속도는 O(n)으로 ArrayList 보다 느리다.
- 엘리먼트의 추가 및 삭제는 LinkedList가 ArrayList보다 빠르다.
- 엘리먼트를 추가 및 삭제하는 중에 array를 리사이즈 하거나 인덱스를 업데이트를 할 일이 없기 때문
- 엘리먼트들은 이전, 다음 엘리먼트들에 대한 정보를 가지고 있기 때문에 ArrayList보다 더 많은 메모리를 소비
- ArrayList
- 랜덤 액세스를 제공하는 컬렉션은 무엇인가?
- ArrayList, HashMap, TreeMap, Hashtable 이 자신의 엘리먼트에 대한 랜덤 엑세스를 제공
- Map, Array, Hash 계열
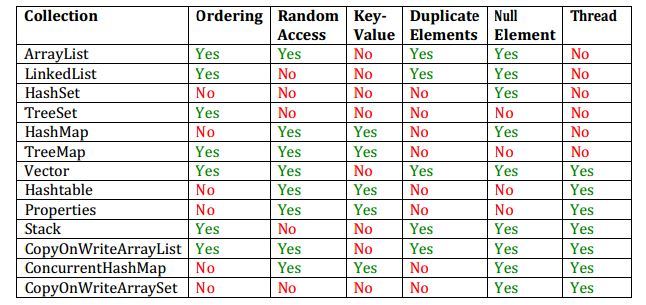
- ArrayList, HashMap, TreeMap, Hashtable 이 자신의 엘리먼트에 대한 랜덤 엑세스를 제공
- EnumSet은 무엇인가?
- Enum 타입을 활용해서 Set을 구현한 클래스
- Set이 생성 될 때 Set 안의 모든 엘리먼트들은 하나의 enum 타입을 구현한 것이어야 한다.
- synchronized되어있지 않고 null 엘리먼트도 허용하지 않는다.
- thread-safe 한 컬렉션 클래스들은 무엇이 있는가?
- Vector, Hashtable, Properties, Stack
- synchronized 되어 있는 클래스
- multi-thread 환경에서도 정삭적으로 동작
- Vector, Hashtable, Properties, Stack
- Concurrent 컬렉션 클래스는 무엇인가?
- thread-safe 하고 iterating 작업 중에 컬렉션을 수정할 수 있는 클래스들을 포함
- 대표적으로 CopyOnWriteArrayList, ConcurrentHashMap,CopyOnWriteArraySet이 있다.
- BlockingQueue는 무엇인가?
- 엘리먼트들을 검색, 삭제 할때 대기하고, 큐에 엘리먼트가 추가 될 때 저장공간이 충분해 질 때까지 기다리는 기능을 제공하는 Queue
- 자바 컬렉션 프레임워크에서 제공하는 인터페이스중에 하나로 주로 producer-consumer 문제에 주로 사용
- producer가 cosumer에게 Object를 전달할때 저장공간 부족에 따르는 여러 문제점을 걱정할 필요가 없다.
- java 에서는 BlockingQueue를 구현한 ArrayBlockingQueue, LinkedBlockingQueue, PriorityBlockingQueue, SynchronousQueue등을 지원
- Queue, Stack 간의 차이점은 무엇인가?
- Queue
- First-In-First-Out(FIFO)를 사용하지만 항상 그러는 것은 아니다.
- Deque 인터페이스를 사용해서 양쪽 끝에서 엘리먼트에 접근할 수 있다.
- Stack
- Last-In-First-Out(LIFO)방식을 사용
- Vector 클래스를 확장해서 사용하지만 Queue는 인터페이스일 뿐이다.
- Queue
- Collections 클래스는 무었인가?
- java.util.Collections 는 유틸리티 클래스로 static 메서드로 구성
- 컬렉션들을 조작하는데 사용
- 다형성을 활용한 알고리즘들을 가지고 컬렉션을 조작
- 컬렉션 프레임워크의 알고리즘(이진 검색, 정렬, 섞기, 뒤집기등)을 포함
- Comparable 인터페이스와 Comparator 인터페이스는 무엇인가?
- Comparable
- key 하나만 가지고 정렬 가능
- compareTo(Object o)
- Comparator
- 정렬할 때 다른 Key를 사용해서 정렬 가능
- compare(Object o1, Object o2)
- Comparable
- Comparable 인터페이스과 Comparator 인터페이스의 차이점은 무엇인가?
- -> 33. 참고
- Object들의 목록을 정렬시키려면 어떻게 해야 되는가?
- Object들의 배열을 정렬해야 될때는 Arrays.sort()를 사용
- Object 목록들을 정렬시키고 싶으면 Collections.sort()를 사용
- Collections는 내부적으로 Arrays 의 sorting 메서드를 사용하고 있고, list를 array로 변환하는 경우를 제외하고 동일한 성능을 보여준다
- 만약 Collections를 함수에 파라미터로 전달할 경우, 이를 수정하지 못하게 할려면 어떻게 해야 되는가?
- 함수로 파라미터를 전달하기 전에 Collections.unmodifiableCollection(Collection c) 메서드를 사용해서 읽기전용 컬렉션을 생성
- 만약 컬렉션을 수정할려는 시도가 생기면 UnsupportedOperationException을 발생
- 함수로 파라미터를 전달하기 전에 Collections.unmodifiableCollection(Collection c) 메서드를 사용해서 읽기전용 컬렉션을 생성
- 기존 컬렉션을 가지고 동기화된 컬렉션을 만들려면 어떻게 해야 되는가?
- Collections.synchronizedCollection(Collection c)를 사용해서 동기화된(thread-safe)한 컬렉션을 만들 수 있다.
- 컬렉션 프레임워크내부에서 구현된 일반 알고리즘들은 무엇인가?
- 정렬, 검색, 섞기, 최소-최대 값 찾기
- Big-O 표기법은 무엇인가? 예를 들어 줄 수 있는가?
- 알고리즘의 성능을 설명해주는 표기법
- 어떤 컬렉션을 사용할지 고려할때 시간, 메모리, 성능에 대한 Big-O 표기법을 기준으로 선택할때가 많다.
- 예1 : ArrayList get(index i)는 엘리먼트의 숫자에 영향을 받지 않고 동일한 성능을 보여주기 때문에 O(1)으로 표기
- 예2 : 배열이나 리스트에 대한 선형 탐색은 엘리먼트를 찾는데 엘리먼트들의 숫자에 영향을 받기 때문에 O(n)으로 표기
- Java 컬렉션 프레임워크의 모범사례는 무엇인가?
- 사이즈가 고정되어 있으면 Array
- 맵에 삽입된 순서되로 iterate를 하고 싶으면 TreeMap
- 중복을 허용하고 싶지 않으면 Set
- 저장할 엘리먼트들의 사이즈를 알 경우에 초기 용량을 지정함으로써 rehashing이나 resizing이 일어나는것을 회피할 수 있다.
- 제너릭스를 사용해서 type-safety 한 상태를 유지하라
- 맵에 키를 사용할때 JDK에서 재공하는 immutable 클래스를 사용하여 사용자 클래스에서 hashCode()와 equals() 구현할 필요가 없게 하라
- 읽기전용 및 동기화, 빈 컬렉션등을 만들때는 Collections에서 제공하는 유틸리티 클래스를 사용하라.
- 이는 코드 재사용성을 높여주고 안정적이며 유지보수 비용을 줄여 준다.
참고
https://www.javacodegeeks.com/2013/02/40-java-collections-interview-questions-and-answers.html